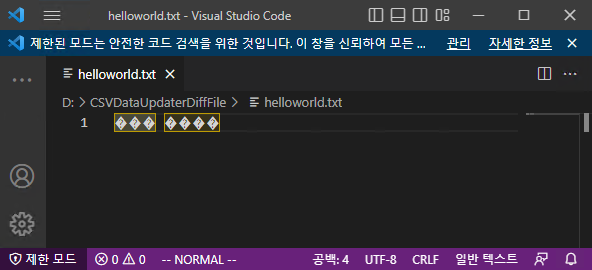
인터넷 프로토콜 상에서 UTF-8 깨짐은 BOM (Byte Order Mark) 문제일 확률이 높은데요,
Windows 환경에서 UTF-8을 사용하면 BOM이 항상 제일 앞에 붙습니다. 반면 인터넷 프로토콜을 공유하는 대다수의 소프트웨어나 단말에서는 UTF-8에서 BOM이 없이 시작하는 경우가 많은데요, BOM을 고려하지 않고 텍스트 인코딩을 시작해서 글자 깨짐이 많이 생기게 됩니다.
일단 파일 자체에서 BOM을 제거하고 저장하는 방법은 텍스트 에디터마다 전부 방법이 다르기 때문에 아래 가이드를 참고하시면 좋을 것 같습니다.
그리고 닷넷에서는 텍스트 인코딩을 할 때 BOM을 넣지 않도록 처리를 하는 것이 도움이 되는데요, 아래 예제처럼 Encoding.UTF8을 쓰면 StreamWriter 출력 시 BOM 3바이트가 붙고, new UTF8Encoding(false)로 UTF8을 쓰면 BOM 3바이트가 붙지 않게 됩니다.
using System;
using System.Text;
using System.Linq;
using System.IO;
public class Program
{
public static void Main()
{
Console.WriteLine("Hello World");
Encoding utf8BOM = Encoding.UTF8;
Encoding utf8 = new UTF8Encoding(false);
String unicodeString =
"This Unicode string has 2 characters outside the " +
"ASCII range:\n" +
"Pi (\u03A0)), and Sigma (\u03A3).";
Console.WriteLine("Original string:");
Console.WriteLine(unicodeString);
Console.WriteLine();
var bomStream = new MemoryStream();
using (var bomSW = new StreamWriter(bomStream, utf8BOM))
{
bomSW.Write(unicodeString);
}
var stream = new MemoryStream();
using (var SW = new StreamWriter(stream, utf8))
{
SW.Write(unicodeString);
}
Console.WriteLine(string.Join(" ", bomStream.ToArray().Take(10).Select(x => string.Format("{0:X2}", x))));
Console.WriteLine(string.Join(" ", stream.ToArray().Take(10).Select(x => string.Format("{0:X2}", x))));
}
}